篇首语:本文由编程笔记#小编为大家整理,主要介绍了第一节:半监督聚类算法概述相关的知识,希望对你有一定的参考价值。
半监督聚类(semi-supervised clustering):传统的聚类学习任务是一种无监督学习任务,也即假设所有样本数据的簇标签未知。但是在某些学习任务中,用户具有某些领域的背景知识,也即约束信息。所以人们希望将这些领域知识应用到聚类任务中,所以这类学习任务称之为半监督聚类。半监督聚类可以分为:
所以半监督聚类主要研究:如何利用少量的约束信息来得到更加准确的聚类结果,同时不仅利用约束样本提供的信息,而且考虑所有无约束样本集所隐含的结构信息
约束信息:约束信息通常被认为是一种背景知识或领域知识,是分析数据时已知的信息。使用约束信息时,通常要对约束信息和无约束样本的关系做出一些假设,常见的有如下三种假设
根据约束存在方式的不同,约束信息分为如下两种
标签约束:在半监督聚类中,虽然整个学习任务是无监督的,但是有一部分数据的标签是可知的。标签约束就是指这种数据的已知标签,它可以看成是一种子集
利用标签约束的半监督聚类算法定义为:对于给定数据集
D
D
D,标签约束集
L
L
L,半监督聚类算法利用
L
L
L中的信息将
D
D
D中数据分配到对应的簇中
成对约束:是一种指明两个实例的相对关系的约束信息;成对约束由以下两个集合构成
利用成对约束的半监督聚类算法定义为:对于给定数据集
D
D
D,必连约束集
M
L
ML
ML,勿连约束集
C
L
CL
CL,半监督算法的目标是通过最小化聚类的目标函数,利用
M
L
ML
ML和
C
L
CL
CL中的信息将
D
D
D中数据分配到对应簇中
下图给出了一个二维空间中数据的成对约束示例,包含两个簇,分别用圆点和三角形表示
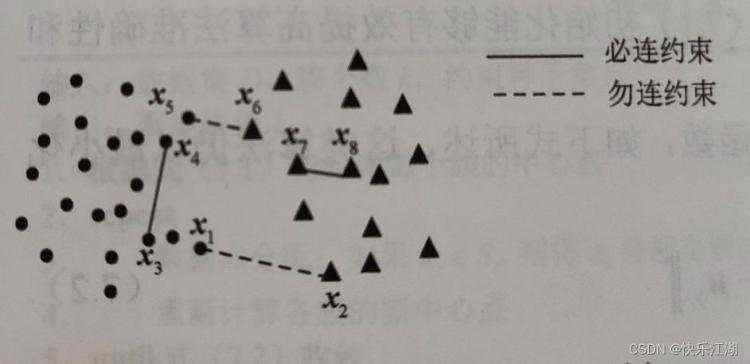
在很多实际问题中(例如图像检索、语音识别、GPS导航等等),往往难以获取数据的簇标签,但是用户可以指定两个实例是否属于同一簇。在给定标签约束的情况下,依然可以生成对应的必连约束和勿连约束






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 